I don't have access to the actual paper, but looking at the linked results[0]:
Core Name Performance (MIPS) Energy (J) Power (W)
Cortex A8 178 25 0.8
Cortex A9 625 11 1.5
Atom N450 978 16 2.5
i7-2700 6089 28 25.5
So A9 delivers 625/1.5 = 417 MIPS per Watt, whereas the i7 delivers 6089/25.5 = 239 MIPS per Watt and the Atom delivers 391 MIPS per Watt.
In addition, their spreadsheet has an "energy" tab calculated from a "normalized" power figure (where Atom comes out on top), but if you multiply the measured figures without the dubious adjustment, it seems that the A9 is actually more efficient (at least when you consider the board power), and MIPS is conspicuously absent from this spreadsheet. So the fundamental conclusion is "either ARM or Intel are better, but it depends on what you measure under what workload".
Something else to keep in mind is that you can get significant power savings when you lower the clock rate. So if you measure total power consumed to run a calculation, it may actually be more efficient to run on a fast CPU, finish quickly, and then drop into a low power state than it would be to run it on a low performance CPU for significantly longer.
This is the sort of factor that people forgot to include when testing SSDs for power/performance metrics in the early days of them being within reach of the average home users. An SSD (especially some of the older models) can pull more power than a good spinning metal drive when running as full force, but what some people didn't factor in was that the SDDs did more in a given time especially with latency sensitive workloads - so to do the same work as the traditional drive it would need to run at run pelt for far less time meaning quite a saving in power.
Another thing modern CPUs do as well as slowing down when under light load is to almost turn parts of themselves off when not needed. These are things that any CPU could potentially do though, it isn't a difference between CISC and RISC designs.
I can't find a good reference now, but supposedly the i7 has a set of transistors that calculates if its workload would execute faster on multiple cores, or fewer cores, and can park cores to save heat, and let the electricity be focused into the unparked cores.
Intel's marketing material in 2008 mentioned the number of transistors doing the load calculations was about equal to the number of transistors in a 486. So you have a 486 constantly determining thread scheduling load, they claimed.
You misunderstood. The CPU doesn't get to decide how many cores are used; the operating system's scheduler does. The CPU just tries to keep an accurate running estimate of its power consumption and uses that to predict whether it has enough headroom to boost the clock speed above the nominal full speed. If some cores are temporarily idled by the OS, then that frees up a lot of power and allows the remaining cores to have their clock speed boosted further.
The operating systems have plenty of knowledge about how CPU power management works. They are hampered somewhat by how things like Turbo Boost are implemented in a backwards-compatible way through ACPI P-states that can't directly convey this information, but it's still pretty straightforward for an OS to support even more complicated schemes like ARM's big.LITTLE.
The real problem is that the OS seldom has enough information about the software workload to know whether it is better run on all cores, or just a few at higher clocks. It falls to application developers to not spawn more worker threads than are necessary.
I wouldn't read too much into the virtues of different ISAs from this comparison. The test processors were all built on different process nodes and even if the node is "32nm" that only means that the minimum feature size is 32nm, other sizing rules might be different and the drive current and leakage almost certainly will be.
Another factor to consider is the rest of the chipset that goes with the CPU. Early Atom based networks and such always used the Atoms along with a chipset that under normal working conditions consumed nearly as much power as the CPU itself, more under certain loads.
ARM up until the 64 bit transition was always one of the CISCiest RISC designs and x86 wasn't nearly as CISCy as, say, VAX. 64 bit ARM is a much more traditional RISC ISA than the previous encoding.
I've always viewed x86 as the worst of both worlds. It lacks the orthogonality of a good CISC, and it lacks the simpleness of a RISC. That modern x86 chips perform so well is despite their inefficient ISA, not because of it. If as much money and research got poured into anything else, it'd perform even better.
I can't believe I'm defending x86 but I think you're being too harsh. Orthogonality isn't really that important these days now that everybody uses compilers and the very messiness of x86 has allowed Intel to keep adding new instructions over time.
Linus waxes poetic on 'rep movs' but I'd rather have something like PAL code for architecture specific optimized routines for implementing copies. Still, that's something most ISAs don't have.
All production ARM hardware retains the old ISA. The 64 bit transition made it more CISCy, not less. Don't confuse an instruction architecture with a CPU.
Yes, essentially all ARM chips are going to support the old ISA. I'm not sure I understand your criticism though? RISC and CISC are terms that always apply to an ISA rather than a CPU, I hope I didn't accidentally imply anything else.
It's important because when people have silly internet wars over this stuff, they end up picking one side or the other because of its effect on actual hardware.
So to say that AArch64 made things simpler is just wrong: all actual 64 bit ARM CPUs in fact implement a more complicated ISA using more die area and more power than their 32 bit predecessors.
In some sense it's more complicated because it's implementing more instruction sets but that's not as big a deal as you might think. ARMs have been doing that for a while, besides the normal A32 ISA there's also Thumb, Jazelle, etc. But while adding ISAs does take some die area it doesn't take too much since ARM instructions are very easy to decode. And that extra die area doesn't cost any power since when you're using A64 you can turn off the A32 decoder.
Now you're doing exactly the same things that Intel people do when ARM folks claim that x86 is hard to decode. :)
Look, by any objective measure, a shipping AArch64 CPU is "more CISCy" than an ARMv7 one. Claiming that it is not because some particular subset of its functionality (that can never be shipped in isolation) is clean is a kind of cognitive dissonance.
I mean, if you want to flame about "architecture subsets", the 8086 was a pretty "clean" architecture too. The datasheet with full instruction set and all addressing modes fit on like 3 pages.
The 8086 instruction set was small but it wasn't a RISC instruction set by any means. It only had a few registers and those it had were tied to fixed semantics. It had microcoded instructions. And many of its instructions involved both memory access and arithmatic. Those features were fine in the 70s but in the 80s they were problematic as people started to use pipelining and things like that.
The when you talk about RISC or CISC you're talking about styles of ISA design influenced by the technical constraints of the eras they arose in. ARM's 64 bit design shares a great many elements with the classic RISC design: 32 registers, 32 bit instructions, load-store, no prediction, etc. It's much more similar to the original RISC processor than ARM's 32 bit design was. If I were designing it I would have gone for for 16 registers and a self synchronizing variable length instruction format arranged around 16-bit chunks more like Thumb. But I'm just some dude who did his thesis on computer architecture then hared off and worked on sensors systems - I don't have any real practical experience so I'm not going to claim that I know better than ARM's engineers.
You can certainly claim that ARMv8 is more complex than ARMv7. But I can't see how you can argue that ARMv8 is less RISC like than ARMv7.
I give up, because you clearly don't see my point. Your using a narrow, essentially academic definition for "[CR]ISC" to justify a real-world sounding argument with terms like "die area" and "power" and "decode". That's insane, sorry.
Last time, then I'm gone: "AArch64 is a simpler RISC ISA architecture" is true, and "AArch64 CPUs have simpler decode units" is false, yet you seem to be arguing the former as evidence for the latter.
I'm afraid I'm still not sure exactly what we're disagreeing about or if we even have a disagreement. If you mean that CPUs that implement AArch64 and AArch32 are going to require more silicon and design effort devoted to their decoders than ARVv7-A CPUs of course I'd agree. If you mean that these CPUs will spend more power decoding when using A64 then I'm not sure but I'd tend to doubt it. If you mean that AArch64 CPUs have more complicated decode units than x86 CPUs than I would confidently disagree (modulo decode width and to a lesser extent clock speed).
If you're saying that the distinction between RISC and CISC isn't very important then I would agree with you, at least for high end processors. Ever since the Pentium Pro people have known how to avoid paying the price for complicated instructions outside of the decode unit and there are CISC instruction sets (not x86) that are relatively easy to decode.
Its not the ISA. Its always been about what simplifying the ISA got you: longer pipelines, simpler register-collision resolution, bigger caches on-chip. That's where the speed came from.
Now that entire complex ISAs can be implemented in a fraction of the real estate of an L0 cache, it matters less. And super-scalar, hyperthreading etc have taken the baton from pipelining.
Right. Ever since the late 90s ISA lost most of its importance on the high end. The most important factor for ISAs these days is probably code density since instruction cache pressure can be an important factor in some workloads.
Ease of decode still matters a bit. IIRC Bulldozer used 5-10% of its power budget on decode and Intel finds it worthwhile to have a cache of decoded instructions. But that's still a relatively small factor in the grand scheme of things.
None of the CPUs compared have very reduced (as in few) number of instructions. We've come quite far from MIPS1, IBM 801 and the first SPARCs in terms of ISA complexity.
The big difference is really that x86 has an ISA->uop decoder, which basically is another decoder in front of the decoder in a RISC.
RISC is ((reduced instruction) set computing), not (reduced (instruction set) computing). That is, the instructions are what's reduced, not the set. What makes an ISA RISC or CISC is how simple or complex each individual instruction is, not how many instructions are in the set.
The point of RISC is that each instruction does one thing and only one thing. There's no addressing modes where a single instruction can access memory, perform some operation on the contents, and write it back into memory. This is why RISC is sometimes described as a strict load/store architecture.
Small simple instruction set, to minimise the size of the decoder
Single cycle execution
Aggressive pipelining
Replacement of decoder space with a much larger on-chip register space
The theory was everything would work faster. And this was true for a while.
But eventually CISC cache killed the register speed advantage, CISC pipelining became astonishingly clever and killed the pipelining advantage, and the actual difference in efficiency between a CISC instruction decoded to u-ops and compiler translation of complex statements to RISC instructions turned out to be somewhere between not much, nothing, and negative.
So RISC basically wins for relatively low performance low power computing. It's not such a win for anything that requires SIMD, MMX, or any kind of DSP extension - which today means most desktop computing.
The basic problem with the premise is that it's more efficient to cache memory reads and decoded instructions and data than to keep data in registers and assume a pipeline is going to give you cache-like performance for instructions.
In fact, modern CISC chips include the equivalent of a hardware compiler that tries to run an optimised internal RISC machine while also providing the benefits of fast data and u-op caching.
The simple many register model is really a bit old fashioned now.
Sort of. The physical register file has more registers than what's specified in the ISA in order to support out-of-order execution. Hardware maps the small number of ISA registers to the larger number of physical registers. All sorts of complex stuff happens in the hardware to make it all work out right (e.g., bypass logic between pipeline stages to make sure dependent instructions are able to use just produced data before it gets stored in the register file). All to give the hardware greater scheduling flexibility.
So yes, there are more registers than you'd think by looking at the ISA, but they aren't available to the compiler, which can limit the kinds of optimizations it can make. I think when AMD introduced x86-64, they only increased ISA registers from 8 to 16. RISC ISAs at the time were offering 32-64 (and some also had larger physical register files to support OoO). Granted these days there's also all of the vector registers for SSE/AVX, but you'll need to have vectorizable code to leverage those.
All that being said, I don't think cache is a replacement for the register file.
RISC is also often described as register-register, as opposed to register-memory or stack or accumulator-based.
In a pure register-register design, all opcodes which use the ALU only operate on data stored in registers, and only store data to registers. Due to this, the only opcodes which touch RAM in such a design are load and store opcodes, and they only use the simplest addressing modes.
In a register-memory design, ALU-using opcodes can touch RAM as well. This is taken to an extreme in accumulator-based designs, which aren't used much now but were previously very popular: One "main" register which is involved in all (or nearly all) opcodes, maybe a couple index registers to make memory addressing easier, and everything else is in RAM. The 6502 is the prototypical accumulator-based design, with the interesting twist that its zero page (all memory addresses with a high byte of 0x00) is almost as fast as registers, making it practically a machine with 256 one-byte registers.
(Stack machines are fairly self-explanatory. I think they're mostly VMs now, because it's easy to take stack machine code, turn it back into a parse tree, and then compile that to optimized machine code.)
Register-register designs are typically RISC, which implies constant-size opcodes (one machine word per) to save on decoding hardware, pipelining built in from the start (so no or few complicated opcodes which can take an unpredictable number of cycles to complete), and a very Spartan design philosophy, even to the extent of making the pipelining architecturally visible by specifying things like branch delay slots (where the opcode immediately after a taken branch opcode is still executed, because it's already in the pipeline). The idea was that the compiler would make it all invisible to the average programmer.
The "no complex opcodes" thing was sometimes taken to extremes: There's no single-cycle algorithm for integer multiplication or division. MIPS therefore had integer multiplication and division opcodes which executed while the rest of the chip was still executing other opcodes: The code would issue a multiplication, say, and then the next n opcodes would be run while the multiplication hardware was cranking through the math; when it was done, the result would be placed in a pair of special registers, called hi and lo. How many opcodes was n? Dunno, it depended on the inputs to the multiplication opcode. Division worked the same way. I don't remember if reading hi and lo early would stall the pipeline or generate garbage...
However, when you remember that the VAX had an opcode which would evaluate a polynomial of arbitrary degree when given an X value and a variable-length list of coefficients, you can kind of see where the RISC folk were coming from.
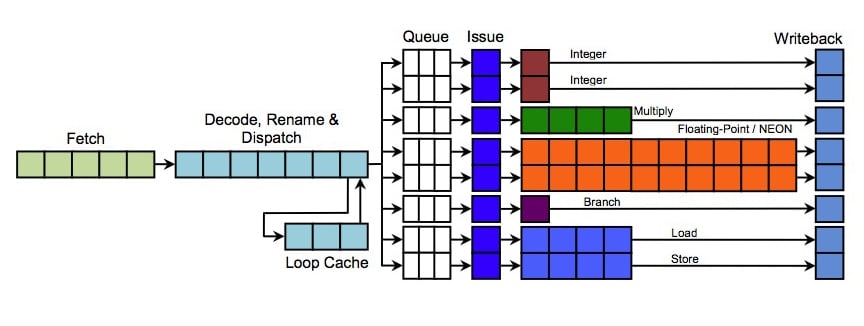
On ARM most of your splitting is going to be breaking out the predication so that the scheduler only has to work with 2 input uops. The thing about x86 is that the instruction stream isn't self-synchronizing, it's hard and occasionally impossible to figure out where the instruction boundaries are if you don't decode progressively from the front. This means that to decode mulitple instructions per clock cycle x86 has to use complicated voodoo.
I don't think simpler to decode necessitates fewer instructions. If all your instructions put the bits describing which registers to use in the same place, use the same way to specify constants instead of registers, to specify that they operate on floating point variables, etc, using 8 bits that select the instruction gives you 256 different discussion with limited added complexity.
Of course, it is unlikely that you can make 256 instructions use the exact same format (some operations will not have any use for 3 registers, for instance) but if you can keep things as consistent as possible, decoding becomes easier. Price paid is that you sacrifice instruction space, for example because the instruction format allows you to write the result of an operation to a register hard-wired to contain a zero.
And x86 isn't that CISC-y. There were processors that basically could do a simple number to string conversion in one instruction, and there _are_ processors with an instruction that does Unicode conversions (http://publibz.boulder.ibm.com/cgi-bin/bookmgr_OS390/BOOKS/d...)
Can you use memory locations as operands in most instructions in the RISC ISAs these days? I always liked that RISC tended to have explicit Load and Store instructions to bring memory values into registers vs. being able to specify a register and a memory address as inputs to an instruction as you can in x86. Decoupling slow memory reads from the op that uses their values gives the CPU more flexibility in scheduling to try and hide the latency of memory ops.
Given that process sizes keep shrinking, and every time you shrink the process size you can fit more on the chip, and heat doesn't scale (as in, the smaller the process size the more heat per in^2), and we're up against a heat wall as it is, we're to the point now where a large chunk of the chip has to be dark at any point in time. As such, CISCs are looking better and better. Because you cannot really scale frequency more (due to heat concerns - freq^2 heat output, to a first approximation), and you have to run most of the chip dark at a time anyways, and you have the space, so you may as well have things that are optimized for rare use cases. And we're already seeing that. The micro-ops on modern x86 processors are getting more and more complex and specialized.
This will especially start happening once we get decent CPU caches - the 3d-ish stacks that are being talked about. Where you have a separate chip stacked under or over the CPU that has a process optimized for RAM.
Note that this is not talking about ISAs, this is talking about the processor itself. Although it's not done much currently, you can just as easily (or rather, with just as much effort) convert a RISC into CISC-like micro-ops (macro-ops?) as convert a CISC into RISC-like micro-ops. It's looking more and more as though ISAs can be successfully decoupled from the actual processor design. Which is encouraging. Treat the instruction encoding as effectively a compression scheme for the instructions that the actual processor runs.
IMHO author is actually missing the point of RISC architecture: instruction homogeneity allows for a simpler (and cheaper) hardware. Of course for software developers RISC or CISC, it actually doesn't matter, that's what abstract layers are all about.
Hundreds of MIPS is interesting, for a certain class of application, but it would be interesting to see the results for sub MIP applications. The microcontroller in a microwave oven.
{kind=link}
In addition, their spreadsheet has an "energy" tab calculated from a "normalized" power figure (where Atom comes out on top), but if you multiply the measured figures without the dubious adjustment, it seems that the A9 is actually more efficient (at least when you consider the board power), and MIPS is conspicuously absent from this spreadsheet. So the fundamental conclusion is "either ARM or Intel are better, but it depends on what you measure under what workload".
[0] http://research.cs.wisc.edu/vertical/wiki/index.php/Isa-powe...