The article gives another reason "A second answer is aesthetic. Ada's syntax is verbose in a way that programmers with a background in C find unpleasant. if X then Y; end if; instead of if (x) { y; }. procedure Sort (A : in out Array_Type) instead of void sort(int* a)."
I think this should not be underestimated. There is a huge number of small C compilers. People write their own C compiler because they want to have one.
That doesn't happen we Ada. Very few people liked Ada enough that they would write a compiler for a subset of the language. For example, an Ada subset similar to the feature set of Modula-2 should be quite doable with a modest effort.
You're right but it's broader than "C folks like terseness."
C is famously hard to read. Before Perl we used to joke that C is a write-only language: you can't understand what your own code means just weeks later.
Combine this with its lack of bounds checking, pointer arithmetic, and other dangerous features, and the result is a language that's macho for geeks: it's hard, it's dangerous, but it's small and it's fast.
It's a motorcycle for nerds. Ada is a tank.
Nerds get to establish dominance over lesser nerds by doing hard stuff in hard languages and making it fast. This bestows nerd street cred: geek cred.
Ada was used by contractors who needed stuff to work and money was no object.
C was used by hackers to do cool hacker stuff that was perceived to be fast and low level.
It's not low level: machine architectures haven't resembled the C abstractions since the 1970s.
I think this was a genuine generational change. I am pretty sure Rust would never have become popular 20 years earlier because the priorities back then were so different (that was the era of languages like Ruby and Pearl where conciseness and low verbosity were the most valued aspects).
When Ada came out a lot of programmers couldn't even touch type. You're right there's a generational change and a lot of of the Ada stuff won:
* strong typing
* lots of annotations
* keywords over syntax, support for long variable and token names
* object focus (Ada 83 had some limitations on inheritance so it wasn't OO strictly speaking)
* exceptions
* large standard library
These things were controversial in the 1980s. They are not today.
One of the big differences between K&R C and C89 is the introduction of function prototypes. Strong typing was certainly considered positive for compiled languages. Of course C is a lot less strict than Ada.
If we compare the Rust subset that has similar functionality as C then there is not much difference. You get 'fn'. The is 'let' but Rust often leaves out the type, so 'int x = 42;' becomes 'let x = 42;' in Rust. Rust has 'mut' but C has 'const'. Rust introduced '=>' and removed '->' from object access and moved it to the return type of a function.
The C language has support for long variable names. Some early linkers didn't, but that's an implementation issue, people were certainly unhappy about that.
C++ started in the 80s. Objects were not controversial back then. The same applies to exceptions.
I don't have a metric for the size of a standard library. For its time, the C library in Unix system had a large number of functions. Later that was split in a C standard part and a POSIX part. But that was for practical reasons. Lot's of non-Unix systems have trouble implementing fork().
I have no clue what you mean with annotations. If you mean non-function annotations along with code, then generally Rust programs don't have those.
Exceptions were controversial into the 90s which is why Java went down that whole checked-exceptions rabbit hole. The argument was that an exception was essentially a GOTO (or even COME FROM) which broke functional abstraction.
The Ariane 5 crash involved an exception and that was the central "Ada is unsafe actually" argument from C people.
In fact "exceptions are bad" is so baked into a lot of C people's brains that they left them out of Go!
Short variable names were a technical limitation in early languages but style guides were still arguing against long, descriptive variable names in languages like C into the 2000s.
Objects were also likewise controversial and you can see that in the design of Ada 83 where they were both inspired by OO languages like smalltalk but also hesitant to adopt stuff like inheritance. Inheritance was again, seen as a way to break encapsulation (it kinda is) but also a lot of object implementations were slow and memory inefficient in the 80s. Smalltalk was pretty much the reason why the Apple Lisa failed as a product.
OO became a massive buzzword in the 90s but by that time it had already been around for quite a long time.
By annotations I mean mostly type annotations, of course there's also aspect annotations and other stuff ex: Ada SPARK.
As Gen-X, in the Usenet flamewars, the C and C++ folks used to call Pascal/Modula-2/Ada advocates as straightjacket programming, whereas they would be called cowboy programmers.
Ironically the author of Fil-C calls classical C, YOLO-C. :)
not just the priorities, the overall skill and education of programmers.
in the 1980/1990's i was a dumb kid. problems of large systems were not in my mind. having to type begin/end instead of {} was, i thought, a valid complaint.
with experience, education, and hindsight, most of the advantages of the ada language were not understood by the masses. if ada came out today, it would have taken off just like rust.
I'd say that if the original Ada was introduced at the same time as Rust development started then people would pick Rust. Ada is also a product of its time would have to be modernized quite a bit.
Given how similar the syntax is of C, C++, Javascript, and Go, I think a language with the syntax of Ada would have a hard time.
I agree. There are quite a few places where they author claims that Ada had a concept first and some language got the same concept later, but the two concepts are different enough that examples would help to show where they are similar.
Especially if we assume that most readers are not Ada experts and that enough languages are mentioned that most people don't know the details of all of them.
The 286 worked perfectly fine. If you take a 16-bit unix and you run it on a 286 with enough memory then it runs fine.
Where it went wrong is in two areas: 1) as far as I know the 286 does not correct restart all instruction if they reference a segment that is not present. So swapping doesn't really work as well as people would like.
The big problem however was that in the PC market, 808[68] applications had access to all (at most 640 KB) memory. Compilers (including C compilers) had "far" pointers, etc. that would allow programs to use more than 64 KB memory. There was no easy way to do this in 286 protected mode. Also because a lot of programs where essentially written for CP/M. Microsoft and IBM started working on OS/2 but progress was slow enough that soon the 386 became available.
The 386 of course had the complete 286 architecture, which was also extended to 32-bit. Even when flat memory is used through paging, segments have to be configured.
The 286 worked perfectly fine as an improved 8086, for running MS-DOS, an OS designed for 8088/8086, not for 286.
Nobody has ever used the 286 "protected mode" in the way intended by its designers.
The managers of "extended memory", like HIMEM.SYS, used briefly the "protected mode", but only to be able to access memory above 1 MB.
There were operating systems intended for 286, like XENIX and OS/2 1.x, but even those used only a small subset of the features of the 286 "protected mode". Moreover, only a negligible fraction of the 286 computers have been used with OS/2 1.x or XENIX, in comparison with those using MS-DOS/DR-DOS.
I think from the price people also expect a similar performance boost as going from 386 to 486. What made Pentium also confusing is that during this time Intel introduced PCI.
From a 486 with VLB to a Pentium with PCI everything became a lot nicer.
We can assume that organizations like NSA have collected a huge amount of traffic that is protected by RSA or EC. So they well have plenty of use for those quantum computers.
It is the paradox of PQC: from a classical security point of view PQC cannot be trusted (except for hash-based algorithms which are not very practical). So to get something we can trust we need hybrid. However, the premise for introducing PQC in the first place is that quantum computers can break classical public key crypto, so hybrid doesn't provide any benefit over pure PQC.
Yes, the sensible thing to do is hybrid. But that does assume that either PQC cannot be broken by classical computers or that quantum computers will be rare or expensive enough that they don't break your classical public key crypto.
I don't think you said (or cited) what you think you said.
Leaving aside that you actually didn't cite a lattice attack paper, the "dual attack" on lattice cryptography is older than P-256 was when Curve25519 was adopted to replace it. It's a model attack, going all the way back to Regev. It is to MLKEM what algebraic attacks were (are?) to AES.
You know you're in trouble in these discussions when someone inevitably cites SIDH. SIDH has absolutely nothing to do with lattices; in fact, it has basically nothing to do with any other form of cryptography. It was a wildly novel approach that attracted lots of attention because it took a form that was pin-compatible with existing asymmetric encryption (unlike MLKEM, which provides only a KEM).
People who bring up SIDH in lattice discussions are counting on non-cryptography readers not to know that lattice cryptography is quite old and extremely well studied; it was a competitor to elliptic curves for the successor to RSA.
With that established: what exactly is the point you think those three links make in this discussion? What did you glean by reading those three papers?
He's obviously not saying that you can "trust blindly" any PQ algorithm out there, just that there are some that have appeared robust over many years of analysis.
He is assessing that the risk of seeing a quantum computer break dlog cryptography is stronger than the risk of having post quantum assumptions broken, in particular for lattices.
One can always debate but we have seen more post quantum assumptions break during the last 15 years than we have seen concrete progress in practical quantum factorisation (I'm not talking about the theory).
It's purely a matter of _potential_ issues. The research on lattice-based crypto is still young compared to EC/RSA. Side channels, hardware bugs, unexpected research breakthroughs all can happen.
And there are no downsides to adding regular classical encryption. The resulting secret will be at least as secure as the _most_ secure algorithm.
The overhead of additional signatures and keys is also not that large compared to regular ML-KEM secrets.
No it's not. This is the wrong argument. It's telling how many people trying to make a big stink out of non-hybrid PQC don't even get what the real argument is.
Perhaps you would care to enlighten us ignorant plebs rather than taunting us?
My understanding (obviously as a non expert) matches what cyberax wrote above. Is it not common wisdom that the pursuit of new and exciting crypto is an exercise filled with landmines? By that logic rushing to switch to the new shiny would appear to be extremely unwise.
I appreciate the points made in the article that the PQ algorithms aren't as new as they once were and that if you accept this new imminent deadline then ironing out the specification details for hybrid schemes might present the bigger downside between the two options.
I mean TBH I don't really get it. It seems like we (as a society or species or whatever) ought to be able to trivially toss a standard out the door that's just two other standards glued together. Do we really need a combinatoric explosion here? Shouldn't 1 (or maybe 2) concrete algorithm pairings be enough? But if the evidence at this point is to the contrary of our ability to do that then I get it. Sometimes our systems just aren't all that functional and we have to make the best of it.
"taunt" in the sense that you dangle some knowledge in front of people and make them beg, not "taunt" in the sense of "insult".
You said:
>"[...] don't even get what the real argument is."
and then refuse to explain what the "real" argument is. someone then asks for clarification and you say:
"It's definitely not [...]""
okay, cool! you are still refusing to explain what the "real" argument is. but at least we know one thing it isnt, i guess.
you haven't even addressed the "mistaken assertion". you just say "nah" and refuse to elaborate. which is fine, i guess. but holy moly is it ever frustrating to read some of your comment chains. it often appears that your sole goal in commenting is to try and dunk on people -- at least that is how many of your comments come across to me.
I was explicit about what the real argument isn't: the notion that lattice cryptography is under-studied compared to RSA/ECC.
I understand what your takeaway from this thread is, but my perspective is that the thread is a mix of people who actually work in this field and people who don't, both sides with equally strong opinions but not equally strong premises. The person I replied to literally followed up by saying they don't follow the space! Would you have assumed that from their preceding comment?
(Not to pick on them; acknowledging that limitation on their perspective was a stand-up move, and I appreciate it.)
You do "XYZ isn't the right argument, ABC is" on a thread like that, and the reply tends to be "well yeah that's what I meant, ABC is just a special case of XYZ". No thanks.
I'm not a professional cryptographer, but I _am_ really interested in opinions of experts in the field and I do have a lot of prior experience with crypto (the actual kind, not *coin). From my point of view, I just don't see what's the fuss is all about.
There's no shared understanding, just a snarky expert claiming (in effect) "I know better than all you simpletons but I'm not going to share". At best it's incredibly poor behavior. At worst it's the behavior of someone who doesn't actually have a defensible point to make.
As far as I know, the currently standardized lattice methods are not known to be vulnerable? And the biggest controversy seemed to be the push for inclusion of non-hybrid methods?
I'm not following crypto closely anymore, I stopped following the papers around 2014, right when learning-with-errors started becoming mainstream.
What surprises me is how non-linear this argument is. For a classical attack on, for example RSA, it is very easy to a factor an 8-bit composite. It is a bit harder to factor a 64-bit composite. For a 256-bit composite you need some tricky math, etc. And people did all of that. People didn't start out speculating that you can factor a 1024-bit composite and then one day out of the blue somebody did it.
The weird thing we have right now is that quantum computers are absolutely hopeless doing anything with RSA and as far as I know, nobody even tried EC. And that state of the art has not moved much in the last decade.
And then suddenly, in a few years there will be a quantum computer that can break all of the classical public key crypto that we have.
This kind of stuff might happen in a completely new field. But people have been working on quantum computers for quite a while now.
If this is easy enough that in a few years you can have a quantum computer that can break everything then people should be able to build something in a lab that breaks RSA 256. I'd like to see that before jumping to conclusions on how well this works.
> Sure, papers about an abacus and a dog are funny and can make you look smart and contrarian on forums. But that’s not the job, and those arguments betray a lack of expertise. As Scott Aaronson said:
> Once you understand quantum fault-tolerance, asking “so when are you going to factor 35 with Shor’s algorithm?” becomes sort of like asking the Manhattan Project physicists in 1943, “so when are you going to produce at least a small nuclear explosion?”
To summarize, the hard part of scalable quantum computation is error correction. Without it, you can't factorize essentially anything. Once you get any practical error correction, the distance between 32-bit RSA and 2048-bit RSA is small. Similarly to how the hard part is to cause a self-sustaining fissile chain reaction, and once you do making the bomb bigger is not the hard part.
This is what the experts know, and why they tell us of the timelines they do. We'd do better not to dismiss them by being smug about our layperson's understanding of their progress curve.
I’ve worked with Bas. I respect him, but he is definitely a QC maximalist in a way. At the very least he believes that caution suggests the public err on the side of believing we will build them.
The actual challenge is we still don’t know if we can build QC circuits that factorize faster than classical both because the amount of qubits has gone from ridiculously impossible to probably still impossible AND because we still don’t know how to build circuits that have enough qbits to break classical algorithms larger or faster than classical computers, which if you’re paying attention to the breathless reporting would give you a very skewed perception of where we’re at.
It’s also easy to deride your critics as just being contrarian on forums, but the same complaint happens to distract from the actual lack of real forward progress towards building a QC. We’ve made progress on all kinds of different things except for actually building a QC that can scale to actually solve non trivial problems . It’s the same critique as with fusion energy with the sole difference being that we actually understand how to build a fusion reactor, just not one that’s commercially viable yet, and fusion energy would be far more beneficial than a QC at least today.
There’s also the added challenge that crypto computers only have one real application currently which is as a weapon to break crypto. Other use cases are generally hand waved as “possible” but unclear they actually are (ie you can’t just take any NP problem and make it faster even if you had a compute and even traveling salesman is not known to be faster and even if it is it’s likely still not economical on a QC).
Speaking of experts, Bas is a cryptography expert with a specialty in QC algorithms, not an expert in building QC computers. Scott Aronson is also well respected but he also isn’t building QC machines, he’s a computer scientist who understands the computational theory, but that doesn’t make him better as a prognosticator if the entire field is off on a fool’s errand. It just means he’s better able to parse and explain the actual news coming from the field in context.
Don't recognise you from your username, but thanks for the respect. (Update: ah, Vitali! Nice to hear from you.)
If you look back at my writing from 2025 and earlier, I'm on the conservative end of Q-day estimates: 2035 or later. My primary concern then is that migrations take a lot of time: even 2035 is tight.
I'm certainly not an expert on building quantum computers, but what I hear from those that are worries me. Certainly there are open challenges for each approach, but that list is much shorter now than it was a few years ago. We're one breakthrough away from a CRQC.
For me presuming Q-day will happen which is why I categorize that more as a maximalist camp, same as people who believe AGI is inevitable are AI maximalists. I could also be misremembering our conversation, but I thought you had said something like 2029 or 2030 in our 2020 conversation :)?
My concern is that there's so much human and financial capital behind quantum computing that the "experts" have lots of reason to try to convince you that it's going to happen any day now. The cryptographic community is rightly scared by the potential because we don't have any theoretical basis to contradict that QC speedups aren't physically possible, but we also don't have any proof (existence or theoretical) that proves they are actually possible.
The same diagrams that are showing physical q-bits per year or physical qbits necessary to crack some algorithm are the same ones powering funding pitches and that's very dangerous to me - it's very possible it's a tail wagging the dog situation.
The negative evidence here for me is that all the QC supremacy claims to date have constantly evaporated as faster classical algorithms have been developed. This means the score is currently 0/N for a faster than classical QC. The other challenge is we don't know where BQP fits or if it even exists as a distinct class or if we just named a theoretical class of problems that doesn't actually exist as a distinct class. That doesn't get into the practical reality that layering more and more error correction doesn't matter so much when the entire system still decoheres at any number at all relevant for theoretically being able to solve non-trivial problems.
Should we prepare for QC on the cryptography side? I don't know but I'm still less < 10% chance that CRQC happens in the next 20 years. I also look at the other situation - if CRQC doesn't ever happen, we're paying a meaningful cost both in terms of human capital spent hardening systems against it and ongoing in terms of slowing down worldwide communications to protect against a harm that never materializes (not to mention all the funding burned spent chasing building the QC). The problem I'm concerned about is that there's no meaningful funding spent trying to crack whether BQP actually exists and what this complexity class actually looks like.
> I could also be misremembering our conversation, but I thought you had said something like 2029 or 2030 in our 2020 conversation
Think that must've been around 2022. It'd have been me mentioning 2030 regulatory deadlines. So far progress in PQC adoption has been mostly driven by (expected) compliance. Now it'll shift to a security issue again.
> My concern is that there's so much human and financial capital behind quantum computing that the "experts" have lots of reason to try to convince you that it's going to happen any day now.
There've been alarmist publications for years. If it were just some physicists again, I'd have been sceptical. This is the security folks at Google pulling the alarm (among others.)
> [B]ut we also don't have any proof (existence or theoretical) that proves they are actually possible.
The theoretic foundation is pretty basic quantum mechanics. It'd be a big surprise if there'd be a blocker there. What's left is the engineering. The problem is that definite proof means an actual quantum computer... which means it's already too late.
> The other challenge is we don't know where BQP fits
This is philosophy. Even P=NP doesn't imply cryptography is hopeless. If the concrete cost between using and breaking is large enough (even if it's not asymptotically) we can have perfectly secure systems. But this is quite a tangent.
> Should we prepare for QC on the cryptography side?
A 10% chance it happens by 2030, means we'll need to migrate by 2029.
> it and ongoing in terms of slowing down worldwide communications
We've been working hard to make the impact negligible. For key agreement the impact is very small. And with Merkle Tree Certificates we also make the overhead for authentication negligible.
The thing is, producing the right isotopes of uranium is mostly a linear process. It goes faster as you scale up of course, but each day a reactor produces a given amount. If you double the number of reactors you produce twice as much, etc.
There is no such equivalent for qubits or error correction. You can't say, we produce this much extra error correction per day so we will hit the target then and then.
There is also something weird in the graph in https://bas.westerbaan.name/notes/2026/04/02/factoring.html. That graph suggests that even with the best error correction in the graph, it is impossible to factor RSA-4 with less then 10^4 qubits. Which seems very odd. At the same time, Scott Aaronson wrote: "you actually can now factor 6- or 7-digit numbers with a QC". Which in the graph suggests that error rate must be very low already or quantum computers with an insane number of qubits exist.
We are stretching the metaphor thin, but surely the progress towards an atomic bomb was not measured only in uranium production, in the same way that the progress towards a QC is not measured only in construction time of the machine.
At the theory level, there were only theories, then a few breakthroughs, then some linear production time, then a big boom.
> Something doesn't add up here.
Please consider it might be your (and my) lack of expertise in the specific sub-field. (I do realize I am saying this on Hacker News.)
Not only, but a huge challenge was manufacturing enough fuel and was the real limiting part. They were working out hard science and engineering but more fuel definitely == bigger bomb in a very real way and it is quite linear because E=mc^2. And it was in many ways the bottleneck for the bombs - it literally guided how big they made the first bomb and the US manufactured enough for 3 - 1 test, 2 to drop
> That graph suggests that even with the best error correction in the graph, it is impossible to factor RSA-4 with less then 10^4 qubits. Which seems very odd.
It's because the plot is assuming the use of error correction even for the smallest cases. Error correction has minimum quantity and quality bars that you must clear in order for it to work at all, and most of the cost of breaking RSA4 is just clearing those bars. (You happen to be able to do RSA4 without error correction, as was done in 2001 [0], but it's kind of irrelevant because you need error correction to scale so results without it are on the wrong trendline. That's even more true for the annealing stuff Scott mentioned, which has absolutely no chance of scaling.)
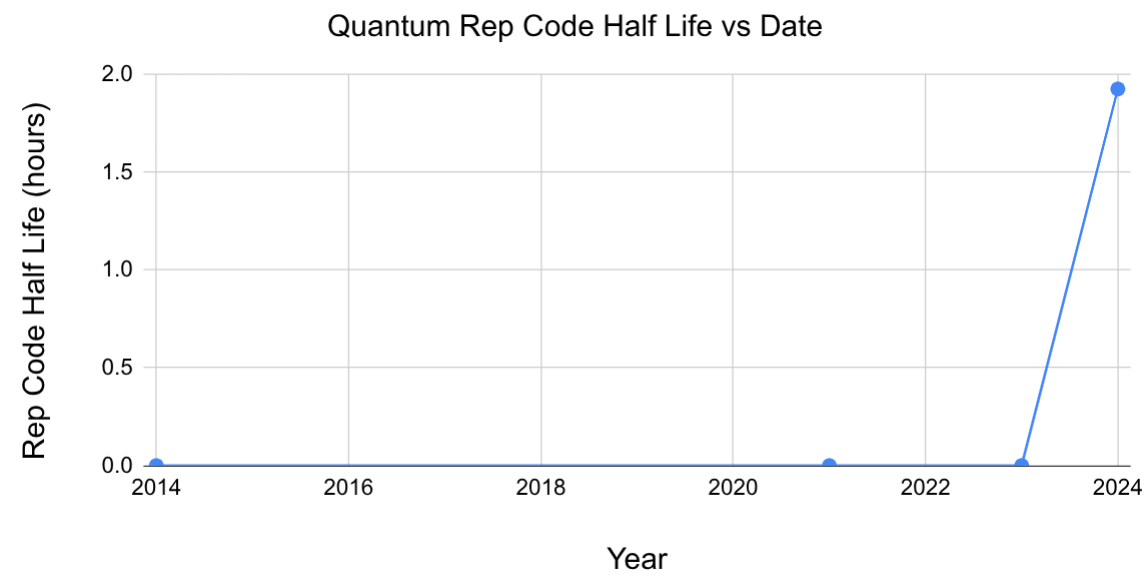
You say you don't see the uranium piling up. Okay. Consider the historically reported lifetimes of classical bits stored using repetition codes on the UCSB->Google machines [1]. In 2014 the stored bit lived less than a second. In 2015 it lived less than a second. 2016? Less than a second. 2017? 2018? 2019? 2020? 2021? 2022? Yeah, less than a second. And this may not surprise you but yes, in 2023, it also lived less than a second. Then, in 2024... kaboom! It's living for hours [4].
You don't see the decreasing gate error rates [2]? The increasing capabilities [3]? The ever larger error correcting code demonstrations [4]? The front-loaded costs and exponential returns inherent to fault tolerance? TFA is absolutely correct: the time to start transitioning to PQC is now.
You can already factor a 6 digit number with a QC, but not with an algorithm that scales polynomially. The graph linked is for optimized variants of Shor's algorithm.
So today you have 1 gram. No bomb. Tomorrow you have 2 grams. Still no bomb.
...
365 days later, you have 365 grams after spending ungodly amounts of energy to separate isotopes. AND STILL NO BOMB! Not even a small one. These scientists are just some bullshit artists.
> Similarly to how the hard part is to cause a self-sustaining fissile chain reaction, and once you do making the bomb bigger is not the hard part.
I don't like this analogy very much, because in practice making a nuclear reaction is much, much easier than making a nuclear bomb. You don't need any kind of enrichment or anything, just a big enough pile of natural uranium and graphite [1].
Making a bomb on the other hand, required an insane amount of engineering: from doing isotope separation to enrich U235 to an absurd level (and / or, extract plutonium from the wastes of a nuclear reactor) to designing a way to concentrate a beyond critical mass of fissile element.
The Manhattan project isn't famous without reason, it was an unprecedented concerted effort that wouldn't have happened remotely as quickly in peacetime.
The Manhattan Project scientists actually did this before anybody broke ground at Los Alamos. It was called the Chicago Pile. And if the control rods were removed and the SCRAM disabled, it absolutely would have created a "small nuclear explosion" in the middle of a major university campus.
Given the level of hype and how long it's been going on, I think it's totally reasonable for the wider world to ask the quantum crypto-breaking people to build a Chicago Pile first.
In truth the Chicago Pile crowd were all about power generation and didn't think it was feasible to make a nuclear bomb ..
( Not impossible, more strictly "beyond reach" economically and processing wise, operating on over estimates of the effort and approach )
They ignored letters from Albet Einstein on the topic, they ignored or otherwise disregarded several letters from the Canadian / British MAUD Committee / Tube Alloys group and it took a personal visit from an Australian for them to sit up and take note that such a thing was actually within reach .. although it'd take some man power and a few challenges along the way.
> And that state of the art has not moved much in the last decade
This is far from true. On the experimental side, gate fidelities and physical qubit numbers have increased significantly (a couple of orders of magnitude). On the theory side, error correction techniques have improved astronomically -- overhead to of error corrections has dropped by many orders of magnitude. On the error correction side progress has been feverish over the last 4 years in particular.
Yeah that's treating D-Wave "breaking" RSA-2048 as the fraud that it is. They didn't factor anything, they computed a square root.
I'm still dubious about the accelerated timeline given what quite a bit of what is presented as progress in the field is fraud or borderline fraud when inspected closely. (e.g. some of the recent majorana claims by Microsoft are at best overhyped, at worst fraud)
If we are looking at the RSA factoring challenge (https://en.wikipedia.org/wiki/RSA_Factoring_Challenge) then 768 bits is done. Breaking RSA 1024 is assumed to be possible but has not been demonstrated in public.
So maybe quantum computers should first complete some of these RSA challenges with less compute resources than done classically before considering any claims about qubits needs as practical.
All of this in the context of DNSSEC or other system using signatures. For encryption the story is different.
There is a huge attack surface for this. For example, kid manages to buy an old phone. Resets the phone and creates an account. Kid buys something like a Pi 3 manages to get a regular phone to become an access point. Etc. If a laptop is not completely locked down, a kid might boot a live USB stick.
The problem is that these laws tend to escalate. Once a government starts regulating, it doesn't stop.
It is also the wrong model. Instead of creating child-safe devices, just like there is a difference between toys and power tools, this regulation pretends that all devices are child safe and parents have to figure out which ones really aren't.
The problem with TAI is that the rest of the world uses UTC. So you can use TAI on a small island and then you have to convert to and from UTC. My hobby kernel is based on TAI internally. And it constantly converts to and from UTC.
You do not use TAI to communicate with the rest of the world, except for certain special purposes.
As you say, what the computer should maintain internally and for communication with other computers, not with humans, is only true time and not other quantities, like the angles between Earth, Sun and stars.
Only TAI is true time, while "universal time" is an angle and "universal time coordinated" (UTC) and its derivatives are some weird hybrid quantities that can be computed from times and angles.
The conversions between true time and various kinds of official times used by humans are very complex and they should be handled in a single place, not in various places that may handle time zones and discrepancies between UTC and TAI and various other "times", e.g. UT2, UT1 etc.
{kind=link}
I think this should not be underestimated. There is a huge number of small C compilers. People write their own C compiler because they want to have one.
That doesn't happen we Ada. Very few people liked Ada enough that they would write a compiler for a subset of the language. For example, an Ada subset similar to the feature set of Modula-2 should be quite doable with a modest effort.
reply